Christopher Michael Sandino1, Frank Ong2, Ke Wang3, Michael Lustig3, and Shreyas Vasanawala2
1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States, 3Electrical Engineering and Computer Sciences, UC Berkeley, Berkeley, CA, United States
1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States, 3Electrical Engineering and Computer Sciences, UC Berkeley, Berkeley, CA, United States
A novel deep subspace learning reconstruction (DSLR+) method is proposed to reconstruct compressed, locally low-rank representations of high-dimensional imaging data enabling high-quality reconstructions with relatively small memory footprint.
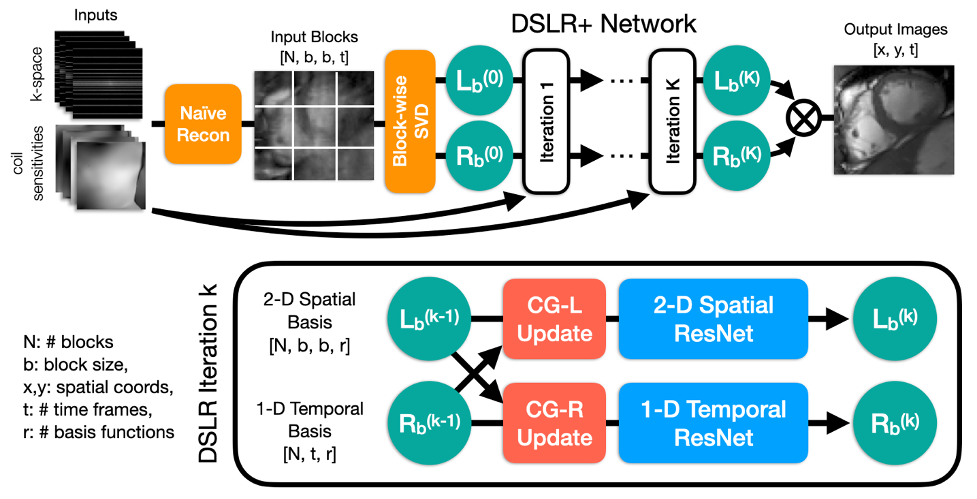
Fig. 2: Undersampled k-space data are reconstructed by zero-filling and then converted into blocks, which are decomposed using SVD to initialize $$$L_b$$$ and $$$R_b$$$. These are iteratively processed by DSLR+ by alternating conjugate gradient and CNN updates. Before each CNN, the basis functions are split into real/imaginary parts and concatenated along the featuredimension. For simplicity, 2-D and 1-D ResNets comprised of 6 convolutions each are used. At the end of the network, the basis functions are combined to form the output images.
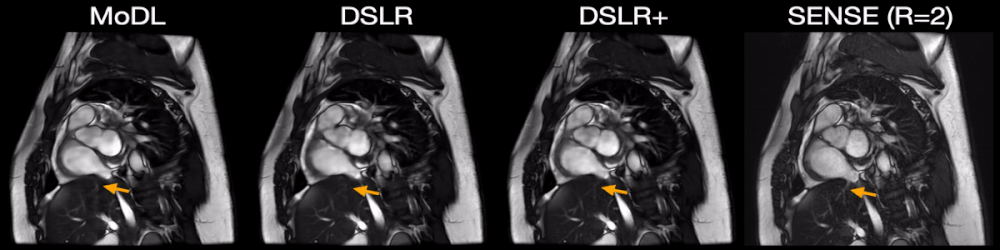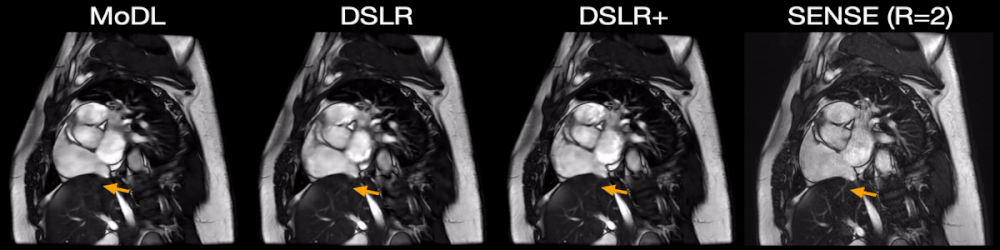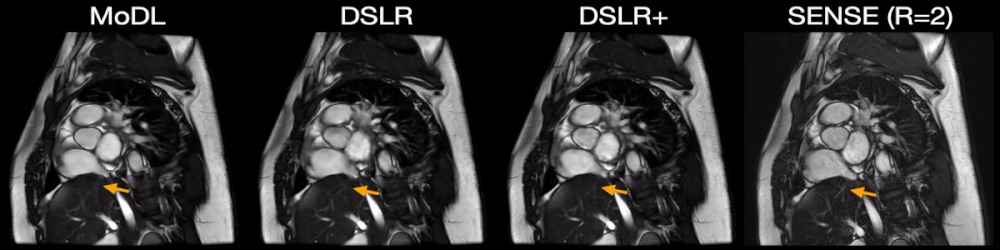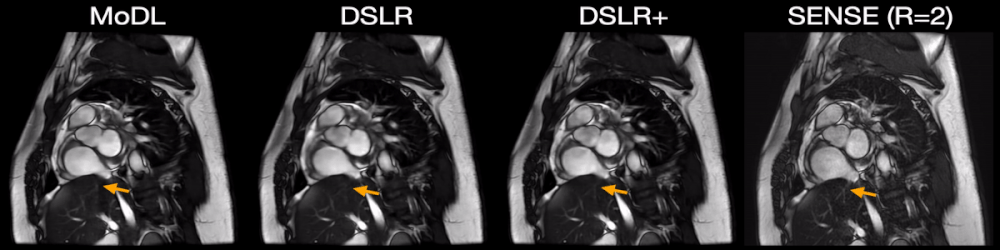
Fig. 5: Two prospectively undersampled scans are performed in a patient with premature ventricular contractions (PVC), which manifests as a double heartbeat motion. The first acquisition is 12X accelerated and reconstructed using MoDL, DSLR, and DSLR+ (left to right). A second acquisition is 2X accelerated and reconstructed with SENSE (rightmost). All show remarkable image quality despite severe acceleration, and never having seen a PVC during training. Both MoDL and DSLR+ faithfully demonstrate the double beat motion, although, DSLR+ depicts less residual aliasing (arrows).
