Yongwan Lim1, Asterios Toutios1, Yannick Bliesener1, Ye Tian1, Krishna S. Nayak1, and Shrikanth Narayanan1
1University of Southern California, Los Angeles, CA, United States
1University of Southern California, Los Angeles, CA, United States
We present the first ever public domain real-time MRI raw dataset for speech production along with synchronized audio and corresponding image time series from a reference reconstruction method for 72 subjects performing 32 linguistically motivated speech tasks.
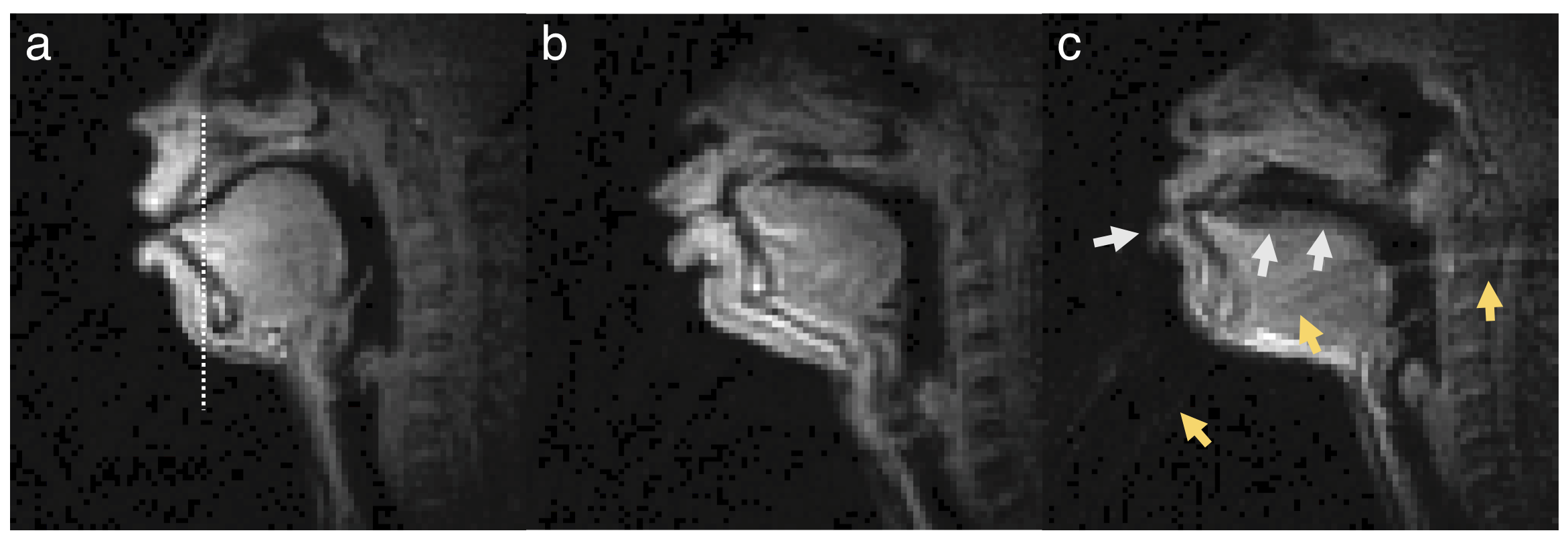
Figure 1. Representative RT-MRI frames from three subjects. The mid-sagittal image frames depict the event of articulating the fricative consonant [Θ] in the word “uthu” where the tongue tip hits the teeth. (a) and (b) are considered to have very high quality (based on high SNR and no noticeable artifact). (c) is considered to have moderate quality (based on good SNR and mild image artifacts); The white arrows point to blurring artifact due to off-resonance while the yellow arrows point to ringing artifact due to aliasing.
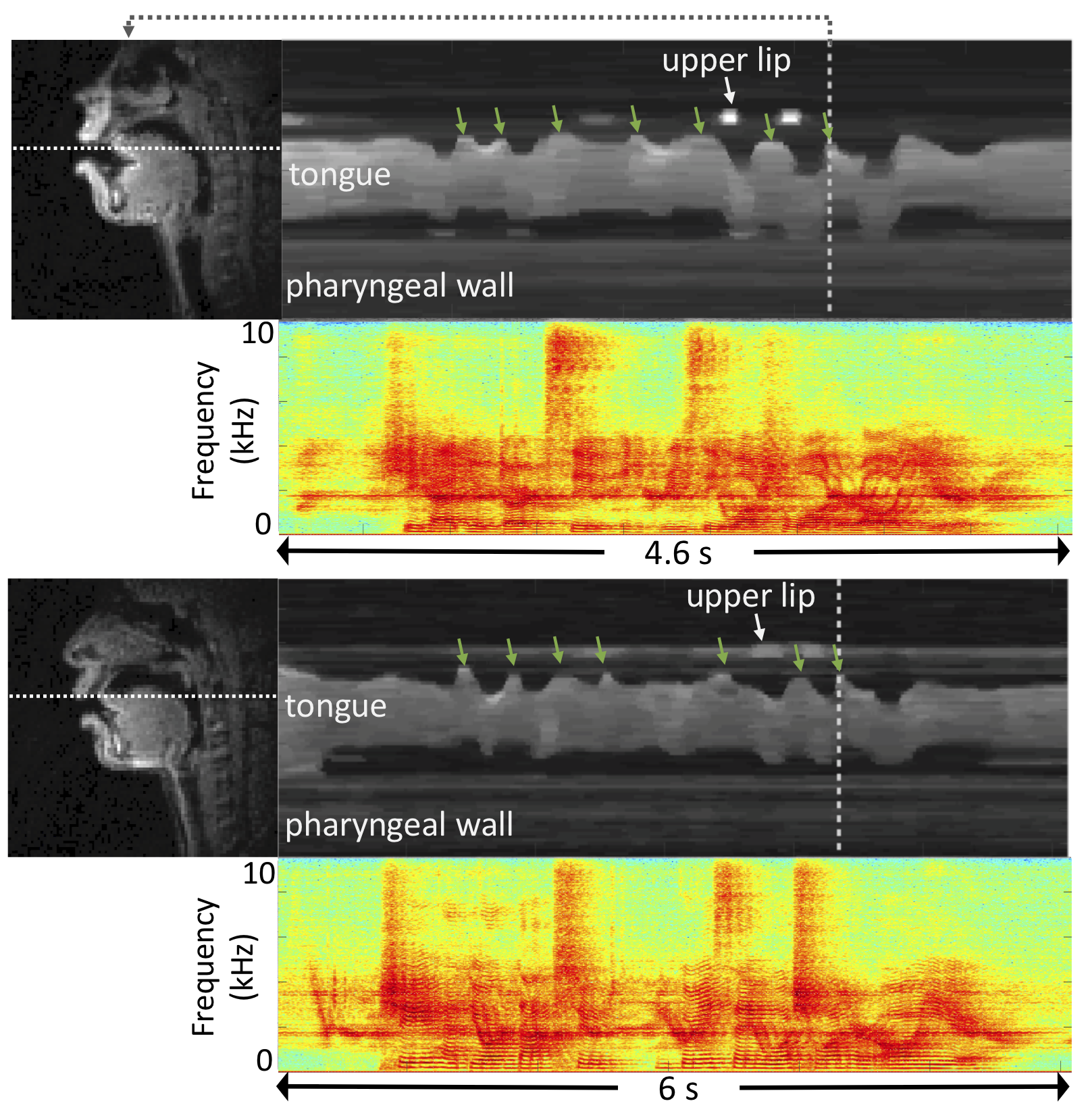
Figure 3. Inter-speaker variability (two representative subjects). The image time profiles shown on the top-right side of each panel correspond to the cut marked by the horizontal dotted line in the image frame shown on the left. The time profile and audio spectrum correspond to the sentence “She had your dark suit in greasy wash water all year”. Green arrows point to several time points where the tongue tip makes contact with teeth. Although both speakers share the critical articulatory events (green arrows), the timing and pattern vary depending on the subject.
