Batu Ozturkler1, Arda Sahiner1, Mert Pilanci1, Shreyas Vasanawala2, John Pauly1, and Morteza Mardani1
1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States
1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States
An interpretable and scalable training method for MRI reconstruction based on convex layer-wise training is presented. The method is evaluated on the fastMRI knee dataset. Our experiments show it attains on par image quality with end-to-end training with less memory footprint for training.
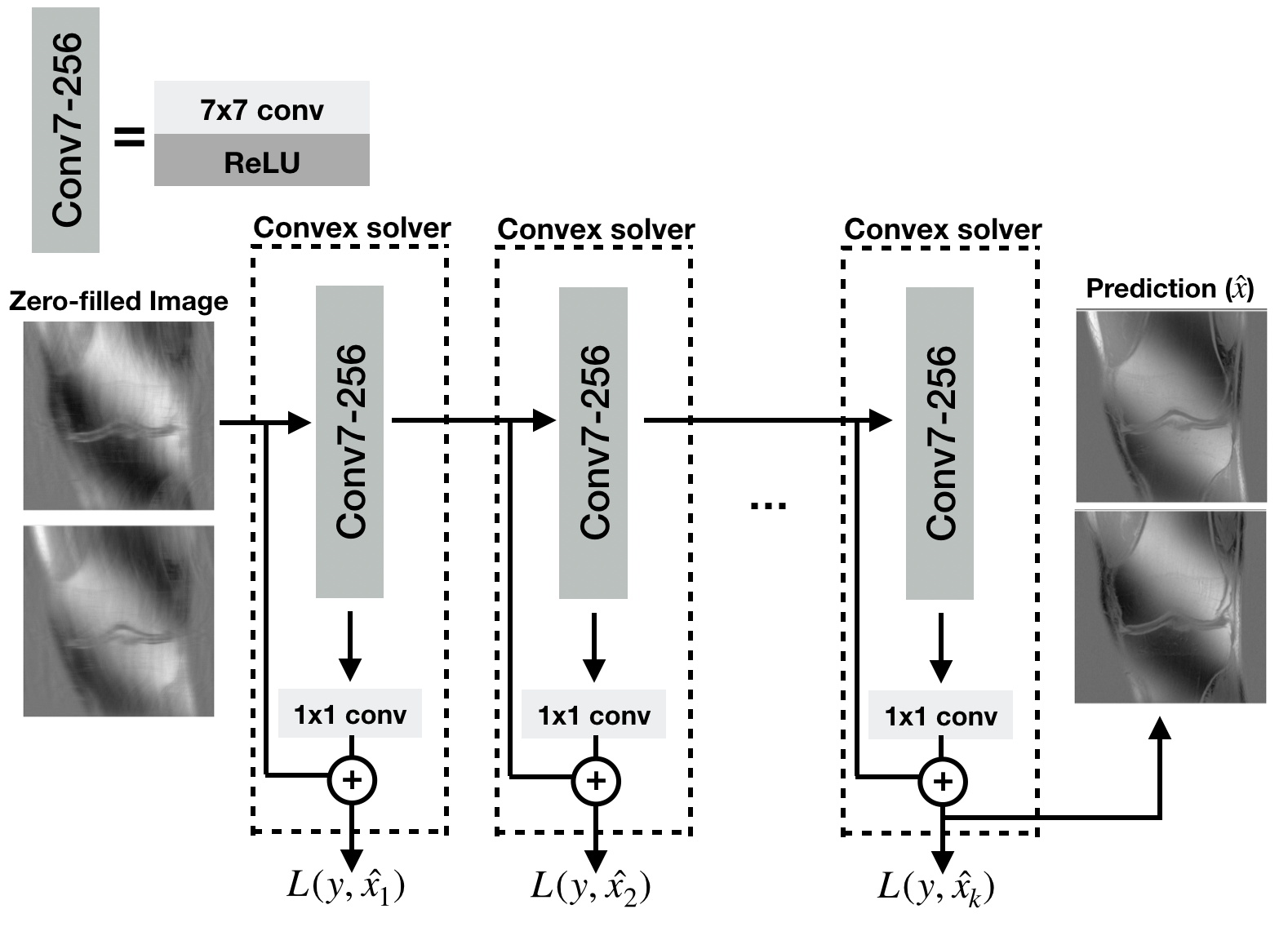
The proposed layer-wise training algorithm. At each training step, a two-layer network is trained to fit the ground-truth. After training has finished, the weights of the first layer are frozen, and the second training step is performed. This training algorithm is repeated k times to obtain a deep network with k+1 convolutional layers. L(y,$$$\hat{x}_i$$$) is the loss for ith step where y is ground-truth, and $$$\hat{x}_i$$$ is the prediction of ith layer. In the final network, each layer except the final layer have 7x7 kernel size and 256 channels, and the final layer has 1x1 kernel size.
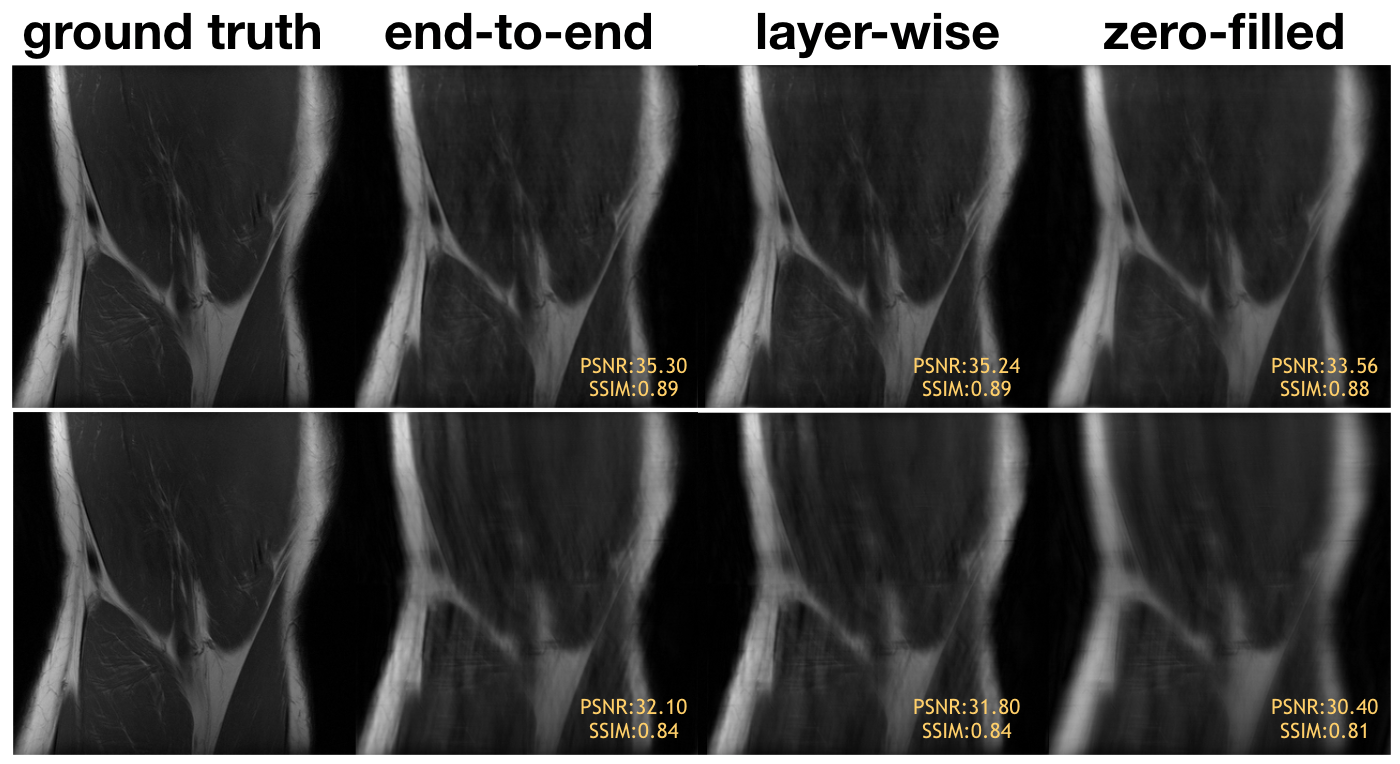
Representative knee images from the test set for layer-wise training vs end-to-end training with Poisson disc sampling (top) and Cartesian sampling (bottom). End-to-end training and layer-wise training have similar perceptual quality.