Katharina Viktoria Hoebel1,2, Christopher P Bridge1,3, Jay Biren Patel1,2, Ken Chang1,2, Marco C Pinho1, Xiaoyue Ma4, Bruce R Rosen1, Tracy T Batchelor5, Elizabeth R Gerstner1,5, and Jayashree Kalpathy-Cramer1
1Athinoula A. Martinos Center for Biomedical Imaging, Boston, MA, United States, 2Harvard-MIT Division of Health Sciences and Technology, Cambridge, MA, United States, 3MGH and BWH Center for Clinical Data Science, Boston, MA, United States, 4Department of Magnetic Resonance, The First Affiliated Hospital of Zhengzhou University, Zhengzhou, China, 5Stephen E. and Catherine Pappas Center for Neuro-Oncology, Massachusetts General Hospital, Boston, MA, United States
1Athinoula A. Martinos Center for Biomedical Imaging, Boston, MA, United States, 2Harvard-MIT Division of Health Sciences and Technology, Cambridge, MA, United States, 3MGH and BWH Center for Clinical Data Science, Boston, MA, United States, 4Department of Magnetic Resonance, The First Affiliated Hospital of Zhengzhou University, Zhengzhou, China, 5Stephen E. and Catherine Pappas Center for Neuro-Oncology, Massachusetts General Hospital, Boston, MA, United States
We show that uncertainty metrics that are extracted from an MC
dropout segmentation model, trained on labels from only one rater, correlate
with the inter-rater variability. This enables the identification of cases that
are likely to exhibit a high disagreement between human raters in advance.
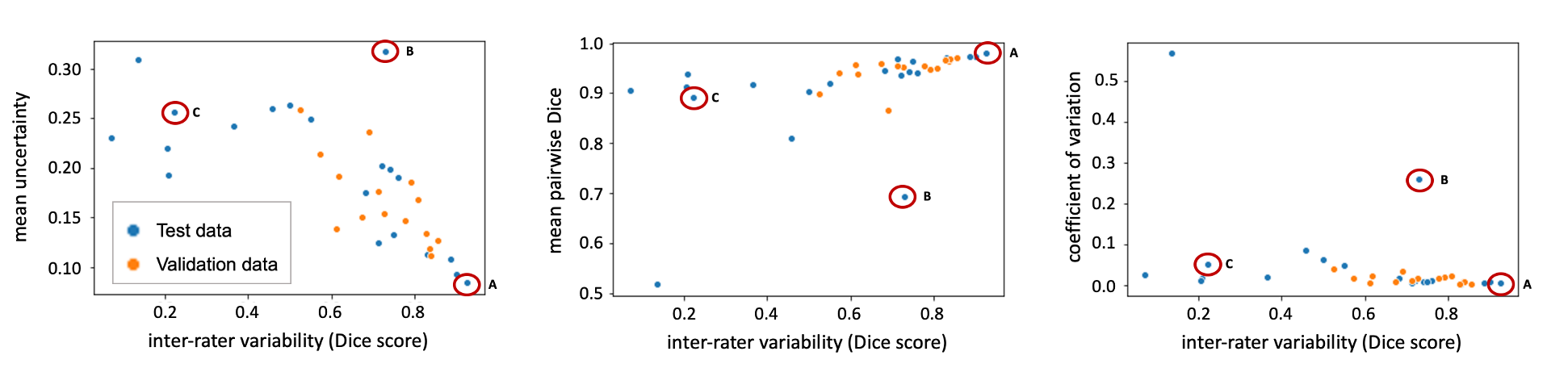
Figure 1: Correlation between the inter-rater Dice
score and uncertainty measures (pooled data from the validation and test
datasets). The marked test cases are shown in Figure 2.
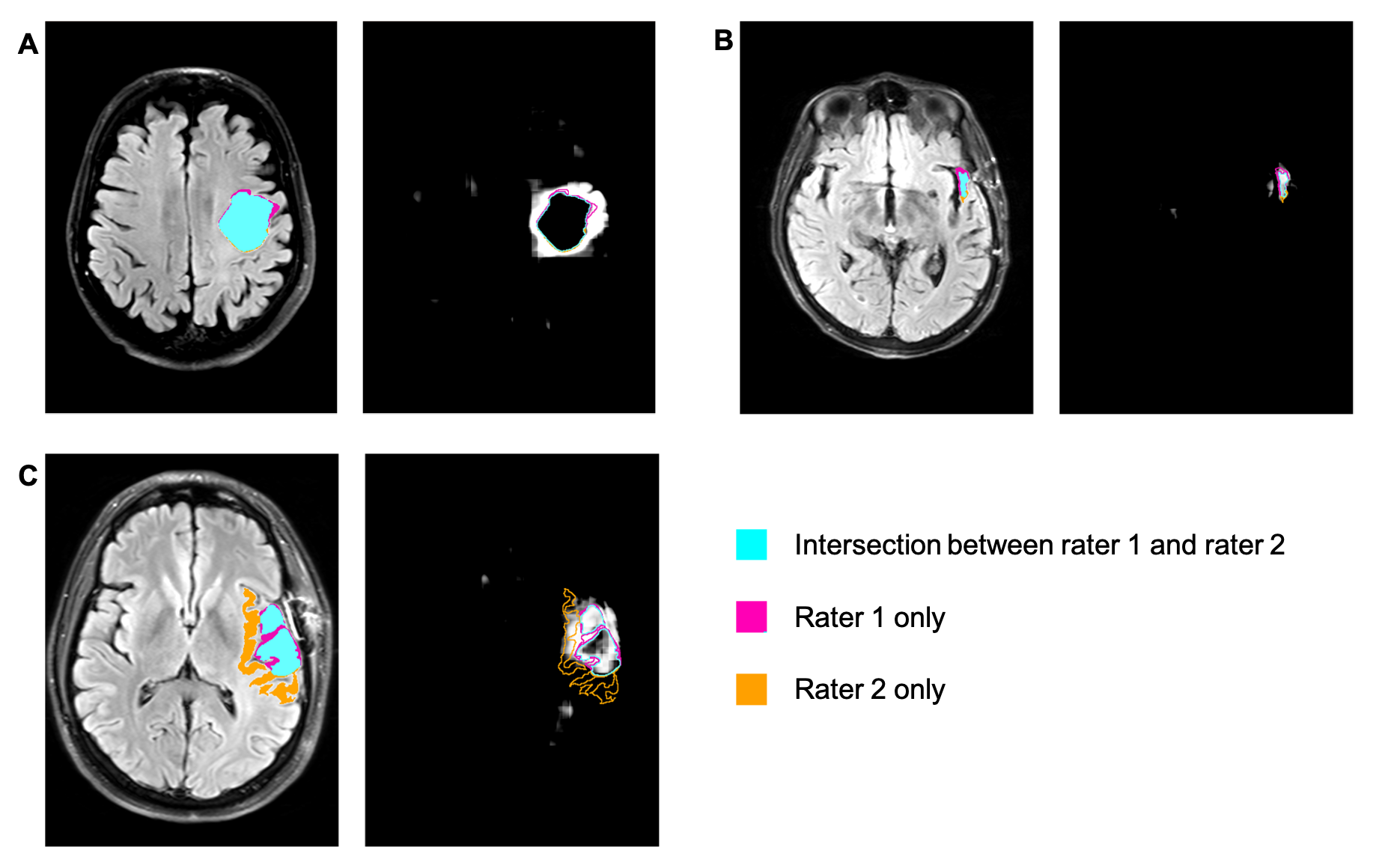
Figure 2: Selected axial slices from three cases
(marked A, B, C in Figure 1). For each of the three cases, the left panel shows
an axial slice of the T2W-FLAIR image with the segmentation labels. The right
panel shows the corresponding uncertainty maps (brighter areas correspond to
higher uncertainty) illustrating areas of high and low uncertainty of the
segmentation model. Segmentation labels: turquoise: overlap between the labels
of rater 1 and 2; magenta: rater 1 only; orange: rater 2 only.
