Satoshi Funayama1,2, Utaroh Motosugi3, and Hiroshi Onishi1
1Department of Radiology, University of Yamanashi, Yamanashi, Japan, 2Graduate School of Medicine, University of Yamanashi, Yamanashi, Japan, 3Department of Radiology, Kofu-Kyoritsu Hospital, Yamanashi, Japan
1Department of Radiology, University of Yamanashi, Yamanashi, Japan, 2Graduate School of Medicine, University of Yamanashi, Yamanashi, Japan, 3Department of Radiology, Kofu-Kyoritsu Hospital, Yamanashi, Japan
Model-based Deep Learning Reconstruction using Folded Image Training Strategy (FITS-MoDL) improved image quality and memory consumption during network training in liver MRI.
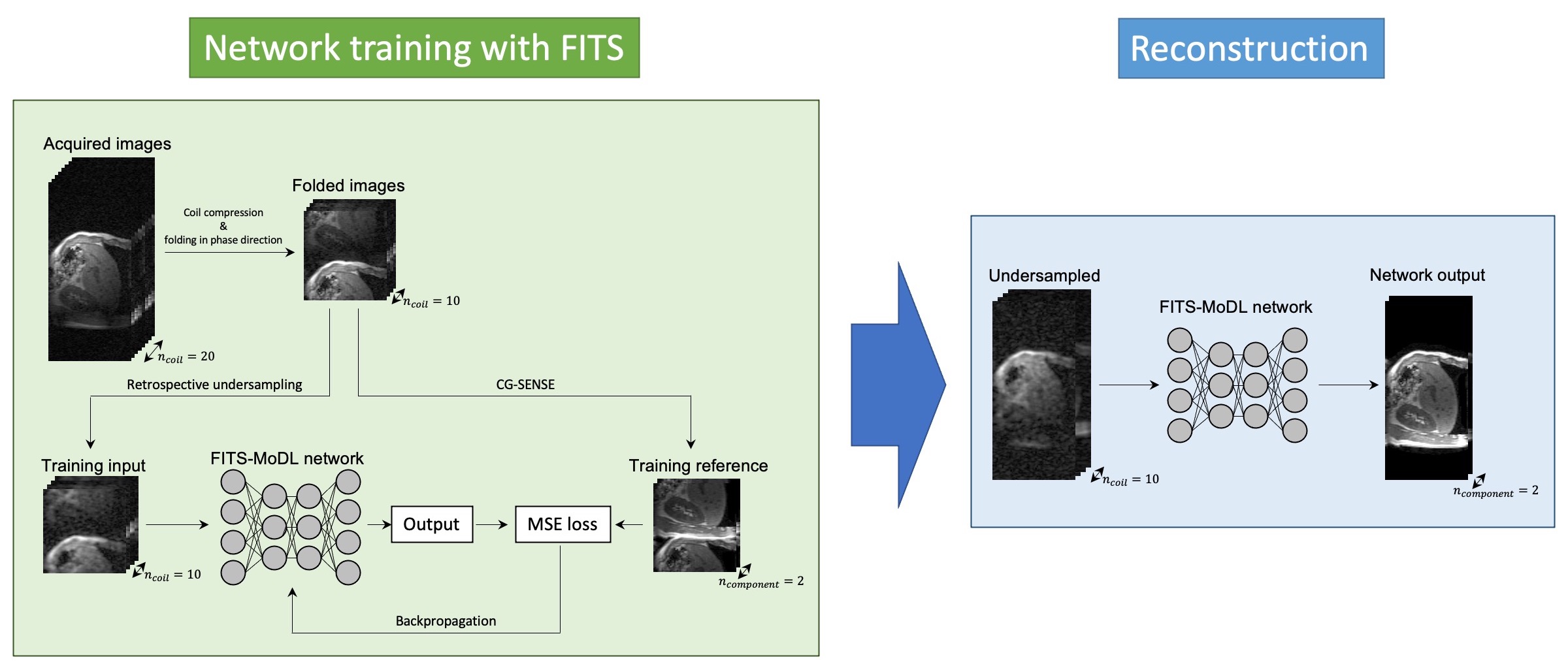
Flow diagram of network training with folded image training strategy (FITS) and image reconstruction. In training with FITS, images for training were folded by factor of 2 to reduce memory consumption.
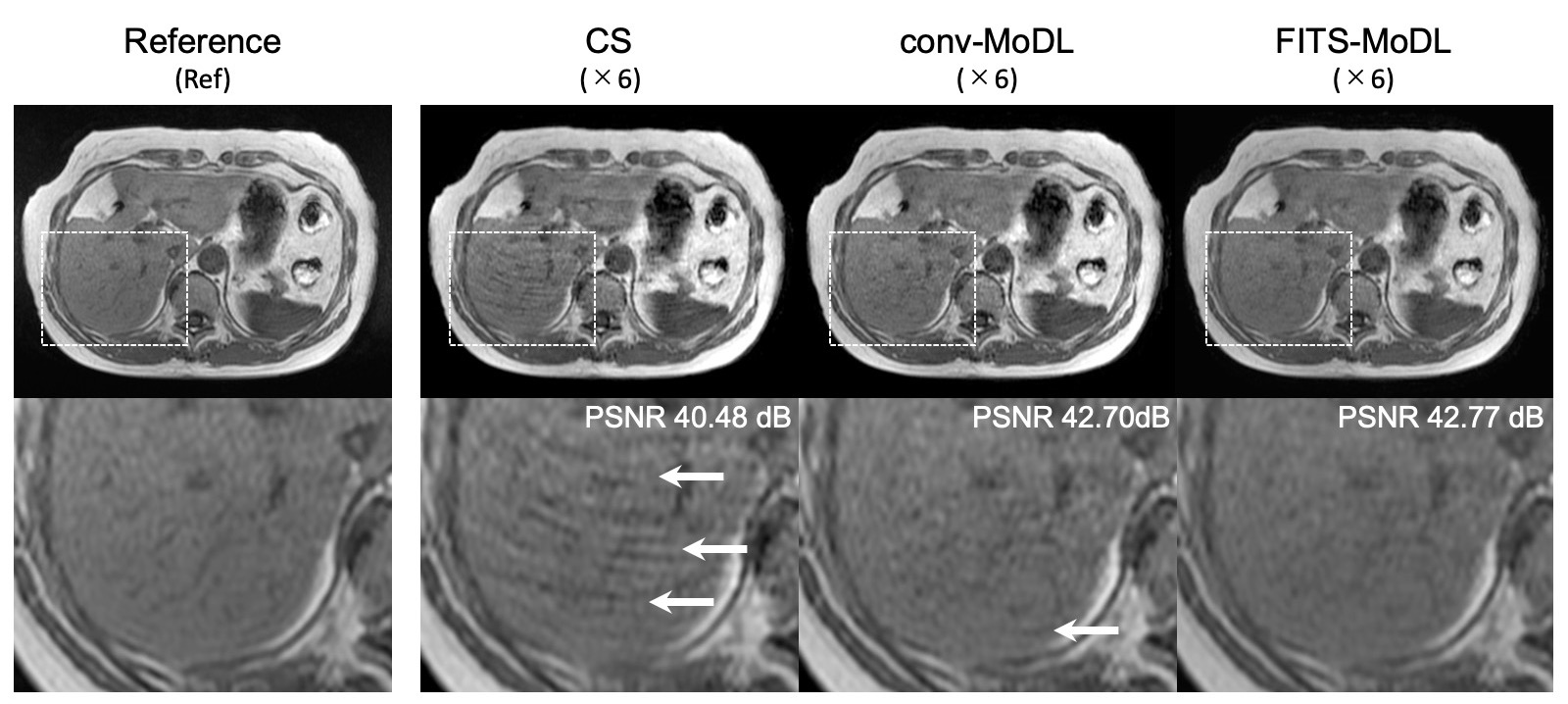
A representative case. (CS) total variation regularized compressed sensing showed some aliasing on liver parenchyma. A few aliasing is remained in the conventional model-based deep learning reconstruction (conv-MoDL), while it is removed in the model-based deep learning reconstruction using FITS (FITS-MoDL).